
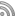
¶ ScrapBook辅助工具之expidxlevels
2011-09-08 13:13
1. 不折腾要死星人
嗯嗯嗯,从,,, 20041214101930 开始,坚持使用SCRAPBOOK :: Firefox Extension 进行离线网页的收集和整理了;
- 一直很爽,而且内置的导出功能,可以一键将本地收集的网页通过一个标准的框架页面,用树状索引进行发布;
- 使用 rsync 等等文件同步小工具,就可以发布一个静态的表述自个儿关注领域技术的纯资料网站了!
- 其实一直以来就发布有这类两个网站:
- 好处是那些优秀的文章,即使原文网站死了,依然在俺这儿原样可查,
- 问题是:
- 导出的那个索引树,随着时间的积累,已经大到无法忍受了!
- 比如说, floss.zoomquiet.org 的树,包含 2万多节点,自身体积已经超过5M
- 有网友吼,用 Chrome 都无法打开!
- 所以:
-
- 得想招精简如此多节点的索引树了,,,
- 为了时不时,在俺这儿打捞历史文章的亲们...
1.1. scraptools
所以,有了 ZoomQuiet / scraptools — Bitbucket
其中的 expidxlevels.py 就是专门进行自动索引化简的...
1.1.1. RDF
以前在相关讲演中吼过,选择 SCRAPBOOK :: Firefox Extension的好点之一,就是有标准的XML 数据输出,好进行二次处理
- 幻灯: http://zoomquiet.org/res/s5/100918-MyTools/rst2s5/
- 录音: http://zoomquiet.org/res/m/r/wav4zoomq/100930-snda-mytools/
- 设想:
-
- 将
scrapbook.rdf(自动生成的记录树关系的RDF)进行合理解析 - 整理成分级索引页面就可以解决单一索引的巨大加载问题了
- 将
- 杯具:
-
- TMD没有一种XML解析库对付的了RDF!
scrapbook.rdf 的设计很简洁:
- 根节点,索引各个
li<RDF:Seq RDF:about="urn:scrapbook:root"> <RDF:li RDF:resource="urn:scrapbook:item20091114162455"/> <RDF:li RDF:resource="urn:scrapbook:item20050206112141"/> </RDF:Seq> - 每个
li也可能是一组Seq<RDF:Seq RDF:about="urn:scrapbook:item20070212000600"> <RDF:li RDF:resource="urn:scrapbook:item20070212000504"/> <RDF:li RDF:resource="urn:scrapbook:item20070212000555"/> </RDF:Seq> - 不论
Seq自身,还是真正的页面,都有一个描述节点来记录详情<RDF:Description RDF:about="urn:scrapbook:item20051216104753" NS2:id="20051216104753" NS2:type="" NS2:title="吉卜力的新作也用blog宣傳" NS2:chars="UTF-8" NS2:comment="" NS2:icon="" NS2:source="http://www.bigsound.org/portnoy/weblog/001318.html" /> - 如果只是分隔线,就是:
<NC:BookmarkSeparator RDF:about="urn:scrapbook:item20091113232313" NS2:id="20091113232313" NS2:type="separator" NS2:title="" NS2:chars="" NS2:comment="" NS2:icon="" NS2:source="" />那么一切就应该从<RDF:Seq RDF:about="urn:scrapbook:root">节点开始爬就好的了,,,
- FT!:
-
- 不论内置的
xml.dom/xml.etree.ElementTree还是伟大的 lxml- 都不支持根据 XML 节点的属性进行搜索!
- 即使可以用 XPath 的算子过滤:
//NC[@RDF:about = "urn:scrapbook:root"],但是,没有库支持完全功能的XPath! - 俺总不能用 XSLT 先写好过滤,然后再调用支持 XSLT 的浏览器获得中间结果給 Py 用吧?!
- 好的,有一堆 RDF 专用解析器
- Redfoot
- RDFAlchemy
- rdflib
- pyrple - An RDF API in Python
- Raptor
- SuRF – Object RDF mapper
- ...可是!那个复杂哪!居然要在使用前,从相关 XSD 网址下载 Scheme 的!
- 也都没有简单的方式,可以让俺搜索到那个该死的
<RDF:Seq RDF:about="urn:scrapbook:root">节点 - 不过,也算开了眼,居然有 RDQL / SPARQL 等专用 RDF 解析语言!
- 看来当年的 Semantic Web 的确玩到了很 HIGH 的程序...
- 可是,对于俺,这么简单的需求,就是没有简单的处置方法嘛?!
- 不论内置的
- 解决:
-
- 冷静了一下,俺只是要进行简单的数据处理,并不一定要真的对 RDF 进行语义上的理解哪?!
- XML 自古就有一种原始的,条带化基于事件的处理模型,曰 SAX
- Py 内置有最简单的 expat库:
- 跟着样例快速完成了处理部分,速度也非常的快
def start_element(name, attrs): if "RDF:Seq" == name: CF.IS_SEQ = 1 CF.IS_DESC = 0 if "urn:scrapbook:root" == attrs['RDF:about']: #print 'ROOT element:', name, attrs CF.IS_ROOT = 1 CF.DICTRDF['ROOT']['id'] = attrs['RDF:about'].split(":")[-1] CF.CRTID = attrs['RDF:about'].split(":")[-1] CF.DICTRDF['ROOT']['li'] = [] else: CF.IS_ROOT = 0 CF.CRTID = attrs['RDF:about'].split(":")[-1] CF.DICTRDF['SEQ'][CF.CRTID] = [] else: CF.IS_SEQ = 0 if "RDF:li" == name: CF.IS_DESC = 0 CF.IS_LI = 1 if CF.IS_ROOT: CF.DICTRDF['ROOT']['li'].append(attrs['RDF:resource'].split(":")[-1]) else: CF.DICTRDF['SEQ'][CF.CRTID].append(attrs['RDF:resource'].split(":")[-1]) elif "RDF:Description" == name: CF.IS_DESC = 1 CF.IS_LI = 0 CF.CRTID = attrs['RDF:about'].split(":")[-1] CF.DICTRDF['DESC'][CF.CRTID] = { 'id':attrs['NS2:id'] ,'type':attrs['NS2:type'] ,'title':attrs['NS2:title'] ,'source':attrs['NS2:source'] ,'chars':attrs['NS2:chars'] ,'icon':attrs['NS2:icon'] ,'comment':attrs['NS2:comment'] }
- 技巧:
-
- 就是用一堆判定,将有限的情况进行区分
- 然后丢到个字典中,供给后续处理
{"ROOT":{'id':'','li':[]} ,"SEQ":{'item...':[] ,,,} ,"DESC":{'item...':{'id':'' ,'type':"" # folder||separator ,'icon':'' ,'title':'' ,'source':'' ,'chars':'' ,'comment':'' } ,,, } }
1.1.2. yeild
好的,有了 RDF 正确的结构关系数据后,怎么优雅的输出成分层的索引页面?!
- 俺习惯用内置的文本模板功能,通过纯文本的嵌套完成 html 的输出
- 结果,发现,俺的网页整理到不同深度的目录中
- 要想进行递归式的树状生成,很容易引发递归过深,Py 崩溃的现象
// scrapbook/chrome/scrapbook.jar->content/scrapbook/output.js 中
processRescursively : function(aContRes)
{
this.depth++;
var id = ScrapBookData.getProperty(aContRes, "id") || "root";
this.content += '<ul id="folder-' + id + '">\n';
var resList = ScrapBookData.flattenResources(aContRes, 0, false);
for (var i = 1; i < resList.length; i++) {
this.content += '<li class="depth' + String(this.depth) + '">';
this.content += this.getHTMLBody(resList[i]);
if (ScrapBookData.isContainer(resList[i]))
this.processRescursively(resList[i]);
this.content += "</li>\n";
}
this.content += "</ul>\n";
this.depth--;
},
- SCRAPBOOK中的原生处理是硬递归的哪,,,
- Py 有优雅的迭代式,但是不那么容易用起来:
- yeild 的递归输出问题
- 引发了社区列表讨论,结果获得的经验很简单:
- 所有想返回的,都用 yeild 包装上!
于是,一切安定团结了,,,
用 shell 包装个命令,想发布本地 SCRAPBOOK 仓库时,一键完成!
1.2. TODO
当然总是有不如意的,留存以后,或是有心人完善了:
- 美化平面索引页面
- 排版和颜色
- CSS 限宽效果用JS 进行动态扩展
- 自动对所有抓取的页面,嵌入原始链接的提示
- 对整体仓库生成 site map 帮助 google 收录 ...
2. 时间帐单
- ~0.01h 起意,要折腾
- 0.5h rdf 理解
- 1h ElementTree 尝试
- 1h lxml 尝试
- ~2h RDF 解析模块收集
- ~1h rdflib 尝试
- ~0.5h 冷静
- ~0.5h expat完成解析
- ~1h 根索引页面输出
- ~2.5h 递归和迭代尝试
- ~2h 获得社区反馈,完成所有功能
合计,~13小时,哗,,,,大大超出原先半天的预计,纠其原因:
- 对XML体系的变态缺乏足够的敬畏
- 对递归的理解一直不扎实
事实证明:嘦不经过真实编程的理解,基本都是误解
动力源自::txt2tags
§
写于: Thu, 08 Sep 2011 | 永久链接;源文:
rdf
,rss
,raw
| 分类: /utility/py4xml
§
[MailMe] [Print]
本作品由Zoom.Quiet创作,采用知识共享署名-相同方式共享 2.5 中国大陆许可协议进行许可。 基于zoomquiet.org上的作品创作。
[MailMe] [Print]
本作品由Zoom.Quiet创作,采用知识共享署名-相同方式共享 2.5 中国大陆许可协议进行许可。 基于zoomquiet.org上的作品创作。


