¶ ScrapBook辅助工具之expidxlevels
嗯嗯嗯,从,,, 20041214101930 开始,坚持使用SCRAPBOOK :: Firefox Extension 进行离线网页的收集和整理了;
- 一直很爽,而且内置的导出功能,可以一键将本地收集的网页通过一个标准的框架页面,用树状索引进行发布;
- 使用 rsync 等等文件同步小工具,就可以发布一个静态的表述自个儿关注领域技术的纯资料网站了!
- 其实一直以来就发布有这类两个网站:
- 好处是那些优秀的文章,即使原文网站死了,依然在俺这儿原样可查,
- 问题是:
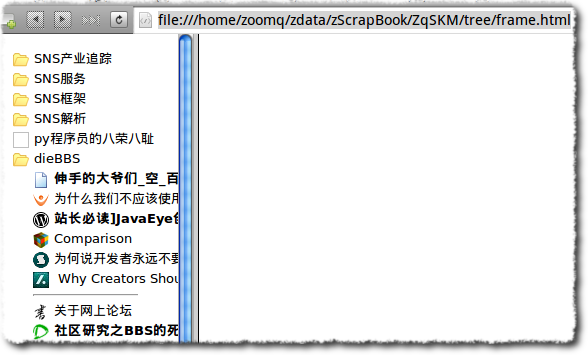
- 导出的那个索引树,随着时间的积累,已经大到无法忍受了!
- 比如说, floss.zoomquiet.org 的树,包含 2万多节点,自身体积已经超过5M
- 有网友吼,用 Chrome 都无法打开!
- 所以:
-
- 得想招精简如此多节点的索引树了,,,
- 为了时不时,在俺这儿打捞历史文章的亲们...
所以,有了 ZoomQuiet / scraptools — Bitbucket
其中的 expidxlevels.py 就是专门进行自动索引化简的...
以前在相关讲演中吼过,选择 SCRAPBOOK :: Firefox Extension的好点之一,就是有标准的XML 数据输出,好进行二次处理
- 设想:
-
- 将
scrapbook.rdf (自动生成的记录树关系的RDF)进行合理解析
- 整理成分级索引页面就可以解决单一索引的巨大加载问题了
- 杯具:
-
scrapbook.rdf 的设计很简洁:
- 根节点,索引各个
li
<RDF:Seq RDF:about="urn:scrapbook:root">
<RDF:li RDF:resource="urn:scrapbook:item20091114162455"/>
<RDF:li RDF:resource="urn:scrapbook:item20050206112141"/>
</RDF:Seq>
- 每个
li 也可能是一组 Seq
<RDF:Seq RDF:about="urn:scrapbook:item20070212000600">
<RDF:li RDF:resource="urn:scrapbook:item20070212000504"/>
<RDF:li RDF:resource="urn:scrapbook:item20070212000555"/>
</RDF:Seq>
- 不论
Seq 自身,还是真正的页面,都有一个描述节点来记录详情
<RDF:Description RDF:about="urn:scrapbook:item20051216104753"
NS2:id="20051216104753"
NS2:type=""
NS2:title="吉卜力的新作也用blog宣傳"
NS2:chars="UTF-8"
NS2:comment=""
NS2:icon=""
NS2:source="http://www.bigsound.org/portnoy/weblog/001318.html" />
- 如果只是分隔线,就是:
<NC:BookmarkSeparator RDF:about="urn:scrapbook:item20091113232313"
NS2:id="20091113232313"
NS2:type="separator"
NS2:title=""
NS2:chars=""
NS2:comment=""
NS2:icon=""
NS2:source="" />
那么一切就应该从 <RDF:Seq RDF:about="urn:scrapbook:root"> 节点开始爬就好的了,,,
- FT!:
-
- 不论内置的
xml.dom / xml.etree.ElementTree 还是伟大的 lxml
- 都不支持根据 XML 节点的属性进行搜索!
- 即使可以用 XPath 的算子过滤:
//NC[@RDF:about = "urn:scrapbook:root"] ,但是,没有库支持完全功能的XPath!
- 俺总不能用 XSLT 先写好过滤,然后再调用支持 XSLT 的浏览器获得中间结果給 Py 用吧?!
- 好的,有一堆 RDF 专用解析器
- 可是,对于俺,这么简单的需求,就是没有简单的处置方法嘛?!
- 解决:
-
- 冷静了一下,俺只是要进行简单的数据处理,并不一定要真的对 RDF 进行语义上的理解哪?!
- XML 自古就有一种原始的,条带化基于事件的处理模型,曰 SAX
- Py 内置有最简单的 expat库:
- 跟着样例快速完成了处理部分,速度也非常的快
def start_element(name, attrs):
if "RDF:Seq" == name:
CF.IS_SEQ = 1
CF.IS_DESC = 0
if "urn:scrapbook:root" == attrs['RDF:about']:
#print 'ROOT element:', name, attrs
CF.IS_ROOT = 1
CF.DICTRDF['ROOT']['id'] = attrs['RDF:about'].split(":")[-1]
CF.CRTID = attrs['RDF:about'].split(":")[-1]
CF.DICTRDF['ROOT']['li'] = []
else:
CF.IS_ROOT = 0
CF.CRTID = attrs['RDF:about'].split(":")[-1]
CF.DICTRDF['SEQ'][CF.CRTID] = []
else:
CF.IS_SEQ = 0
if "RDF:li" == name:
CF.IS_DESC = 0
CF.IS_LI = 1
if CF.IS_ROOT:
CF.DICTRDF['ROOT']['li'].append(attrs['RDF:resource'].split(":")[-1])
else:
CF.DICTRDF['SEQ'][CF.CRTID].append(attrs['RDF:resource'].split(":")[-1])
elif "RDF:Description" == name:
CF.IS_DESC = 1
CF.IS_LI = 0
CF.CRTID = attrs['RDF:about'].split(":")[-1]
CF.DICTRDF['DESC'][CF.CRTID] = {
'id':attrs['NS2:id']
,'type':attrs['NS2:type']
,'title':attrs['NS2:title']
,'source':attrs['NS2:source']
,'chars':attrs['NS2:chars']
,'icon':attrs['NS2:icon']
,'comment':attrs['NS2:comment']
}
- 技巧:
-
- 就是用一堆判定,将有限的情况进行区分
- 然后丢到个字典中,供给后续处理
{"ROOT":{'id':'','li':[]}
,"SEQ":{'item...':[]
,,,}
,"DESC":{'item...':{'id':''
,'type':"" # folder||separator
,'icon':''
,'title':''
,'source':''
,'chars':''
,'comment':''
}
,,,
}
}
好的,有了 RDF 正确的结构关系数据后,怎么优雅的输出成分层的索引页面?!
- 俺习惯用内置的文本模板功能,通过纯文本的嵌套完成 html 的输出
- 结果,发现,俺的网页整理到不同深度的目录中
- 要想进行递归式的树状生成,很容易引发递归过深,Py 崩溃的现象
// scrapbook/chrome/scrapbook.jar->content/scrapbook/output.js 中
processRescursively : function(aContRes)
{
this.depth++;
var id = ScrapBookData.getProperty(aContRes, "id") || "root";
this.content += '<ul id="folder-' + id + '">\n';
var resList = ScrapBookData.flattenResources(aContRes, 0, false);
for (var i = 1; i < resList.length; i++) {
this.content += '<li class="depth' + String(this.depth) + '">';
this.content += this.getHTMLBody(resList[i]);
if (ScrapBookData.isContainer(resList[i]))
this.processRescursively(resList[i]);
this.content += "</li>\n";
}
this.content += "</ul>\n";
this.depth--;
},
- SCRAPBOOK中的原生处理是硬递归的哪,,,
- Py 有优雅的迭代式,但是不那么容易用起来:
于是,一切安定团结了,,,
用 shell 包装个命令,想发布本地 SCRAPBOOK 仓库时,一键完成!
当然总是有不如意的,留存以后,或是有心人完善了:
- 美化平面索引页面
- 排版和颜色
- CSS 限宽效果用JS 进行动态扩展
- 自动对所有抓取的页面,嵌入原始链接的提示
- 对整体仓库生成 site map 帮助 google 收录 ...
- ~0.01h 起意,要折腾
- 0.5h rdf 理解
- 1h ElementTree 尝试
- 1h lxml 尝试
- ~2h RDF 解析模块收集
- ~1h rdflib 尝试
- ~0.5h 冷静
- ~0.5h expat完成解析
- ~1h 根索引页面输出
- ~2.5h 递归和迭代尝试
- ~2h 获得社区反馈,完成所有功能
合计,~13小时,哗,,,,大大超出原先半天的预计,纠其原因:
- 对XML体系的变态缺乏足够的敬畏
- 对递归的理解一直不扎实
事实证明:嘦不经过真实编程的理解,基本都是误解
动力源自::txt2tags
# -*- coding: utf-8 -*-
"""py - html Parser
- refactory py2pre.py from xhtml.py
Copyright (c) 2011 Zoom.Quiet
All rights reserved.
Redistribution and use in source and binary forms are permitted
provided that the above copyright notice and this paragraph are
duplicated in all such forms and that any documentation,
advertising materials, and other materials related to such
distribution and use acknowledge that the software was developed
by the zoomquiet.org. The name of the
University may not be used to endorse or promote products derived
from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED ``AS IS'' AND WITHOUT ANY EXPRESS OR
IMPLIED WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
"""
## Leo: tab_width=-4 page_width=80
__version__ = "v11.09.7"
__author__ = 'Zoom.Quiet '
__url__ = "http://blog.zoomquiet.org/pyblosxom/techic/PyBlosxom/plugins/py2pre.html"
__description__ = ".py export hmtl entry with syntaxhighlighter."
#from Pyblosxom import tools
def cb_entryparser(entryparsingdict):
"""
Register self as plain file handler
"""
entryparsingdict["py"] = parse
return entryparsingdict
def parse(filename, request):
#import os
entrydata = {}
source = open(filename, "r").read()
#print filenames
body = '%s ' % source
entrydata = {'body' : body
,'title' : filename.split("/")[-1]
}
return entrydata
嗯嗯嗯,一清点,居然这么长时间没有发布正式点的 blog 了哪!
- 想恢复每周的心得汇报,但是,俺有强迫症!
- PyBloxom 非常好玩,好用
- 但是,一直不甚完美
- 不过,这也是俺喜欢她的原因~
所有不完美之处,都可以自行 hacking!
- 所以:
-
- 安装了 Disqus
- 升級了 SyntaxHighlighter
- 修复了 py.py
- 修复了内置的分类索引
一直以来,PyBlosxom 没有内置一个靠谱的评注系统,是个囧事儿,
之前,俺为了节省流量,使用了 官方提供的 hosting...
- 结果伟大的功夫网,总是令展示效果不理想!
- 现在想通了,直接升级 到 SyntaxHighlighter 3.0.83
- 并指向本地的各种资源
- 比较贴心的是,这次有了 Dynamic Brush Loading
- 不用象以往,逐一JS 的加载了
function path(){
var args = arguments;
var result = [];
for(var i = 0; i < args.length; i++){
result.push(args[i].replace('@', '/pybshare/syntaxhighlighter_3.0.83/scripts/'));
};
return result;
};
SyntaxHighlighter.autoloader.apply(null, path(
'applescript @shBrushAppleScript.js',
'bash shell @shBrushBash.js',
'css @shBrushCss.js',
'diff patch pas @shBrushDiff.js',
'erl erlang @shBrushErlang.js',
'js jscript javascript @shBrushJScript.js',
'text plain @shBrushPlain.js',
'py python @shBrushPython.js',
'sass scss @shBrushSass.js',
'sql @shBrushSql.js',
'xml xhtml xslt html @shBrushXml.js'
));
SyntaxHighlighter.all()
- PS:
-
- 也有更加轻量的 prettify
- 但是,没有 SyntaxHighlighter 的高亮功能
- 而且,已经和 t2t 深度定制过,使用很好,也就不追赶了,,,
1.5 的插件体系好象有所变化,不那么简单的可以理解了,,,
py2pre.py
- 意图:
-
- 简单的将目录中的 .py 脚本渲染成合适的 html 展示
- 问题:
-
- 解决:
-
- 技巧:
-
- 直接复用 SyntaxHighlighter 的效能
- 将所有脚本内容丢到约定的
<pre> 中就好
#...
def parse(filename, request):
entrydata = {}
source = open(filename, "r").read()
body = '<pre class="brush: python">%s</pre>' % source
entrydata = {'body' : body
,'title' : filename.split("/")[-1]
}
return entrydata
这货不是 PyBlosxom 标准插件,只是发布辅助脚本
- 问题:
-
- 发现使用
pyblosxom-cmd staticrender --config </path/2/config.py> 生成的静态页面,分类索引页面有问题:
- 正常的分类索引中,只包含目录中一个文章
- 如果是 非内容目录,比如说py 脚本目录,倒是可以包含所有内容,可页面输出又有乱码
- 尝试:
-
- 吼了列表,没人理
- 也忘记以前是否正当了
- 追踪代码:
Traceback (most recent call last):
File "/usr/local/bin/pyblosxom-cmd", line 25, in <module>
sys.exit(command_line_handler("pyblosxom-cmd", sys.argv))
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/commandline.py", line 466, in command_line_handler
return f(command, argv)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/commandline.py", line 362, in run_static_renderer
return p.run_static_renderer(options.incremental)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/pyblosxom.py", line 409, in run_static_renderer
tools.render_url_statically(config, url, q)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/tools.py", line 940, in render_url_statically
response = render_url(cdict, url, querystring)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/tools.py", line 983, in render_url
p.run(static=True)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/pyblosxom.py", line 182, in run
blosxom_handler(self._request)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/pyblosxom.py", line 947, in blosxom_handler
renderer.render()
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/renderers/blosxom.py", line 330, in render
content = self.render_content(self._content)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/renderers/blosxom.py", line 273, in render_content
self.render_template(parse_vars, "story", override=1))
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/renderers/blosxom.py", line 370, in render_template
{"entry": entry, "template": template})
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/renderers/blosxom.py", line 405, in _run_callback
defaultfunc=lambda x:x)
File "/usr/local/lib/python2.6/dist-packages/Pyblosxom/tools.py", line 780, in run_callback
output = func(input)
File "/home/zoomq/workspace/3hg/zoomquiet-default/pyblosoxm/zoomquiet/plugins/preformatter/markdown-plugin.py", line 44, in cb_story
...
日!这么深的调用栈?!
pyblosxom-cmd 命令工具
|
+-> commandline.py 解析参数,准备环境
|
+-> pyblosxom.py 调用工具
^ |
| +-> tools.py 组织插件,参数
| |
+----<-----+ 嗯嗯嗯?!回调 pyblosxom.py
使用 renderer.render() 和动态网站流程一样,输出内容
- FT! 具体分类目录在哪个环节生成基本找遍不到了,,,因为将所有需要渲染的,都丢到一个列表中了,,
- 解决:
-
- 其实复杂的技术问题,总是有很2的解决方案的
- 既然难以解决原有的渲染问题,那么 使用期待的页面替换有问题的就KO的哈!
- 俺的 category_static.py 插件生成的树状索引: category-index.html 很可以
- 那么对其进行相关裁剪,复制到对应目录中不就得了!?
先小小的增补一下category_static.py
# ...
for e in etree[p][1:]:
body += '<span id="%s" class="indents">%s</span><a href="%s%s.html">%s</a><br>\n'%(
"/".join(etree[p][0])
,"..."*len(etree[p][0])
,_baseurl
,e[1]
,e[0]
)
- 在前导空间的span 中增加代表文章所在分类目录的 id
那么 cp4idx2category.py就可以简单的完成了:
# -*- coding: utf-8 -*-
'''
将 category_static.py 生成的树状分类索引页面,复制并修订为各个目录中的 index.html
'''
__version__ = 'cp4idx2category v11.09.7'
__author__ = 'Zoom.Quiet <zoomquiet+pyb at gmail dot com>'
import os
import sys
import re
import shutil
def cp4gen(path):
IDX = "%s/category-index.html"% path
p = re.compile("%s\/\d{4}"%path )
for root, dirs, files in os.walk(path):
if path == root:
pass
elif p.match(root):
pass
elif "plugin_info" in root:
pass
else:
aimpath = root.replace(path,"")
exp = ""
for i in open(IDX,'r'):
if '<span id="' in i:
if aimpath in i:
exp += i
else:
exp += i
open("%s/index.html"% root,"w").write(exp)
return
if __name__ == '__main__': # this way the module can be
if 2 != len(sys.argv):
print """ %s usage::
$ python cp4idx2category.py path/2/_static
| +- 生成的静态页面入口
+- 脚本自身
""" % VERSION
else:
path = sys.argv[1]
cp4gen(path)
只要每次,完成静态整站渲染后,用cp4idx2category.py刷一下,就KO!
不断维护的完美之折腾...
- PyBlosxom 静态化发布体系:
-
- Hg/Git 的 hooks 开发部署
- dot 的自动包含图片热区定义的 t2t 处理
- Leo 中的自动化发布脚本按钮
- ~0.01h 起意,要折腾
- ~.5h SyntaxHighlighter升級
- ~2.5h DISQUS 加装,主要是注册和文档查阅耗时
- ~1h 列表吼,E文真的很难以表述清楚...
- ~1h py2pre.py 重构完成
- ~1h cp4idx2category.py 山寨完成
- ~1.5h 记录成文
合计,7小时,哗,,,,
动力源自::txt2tags
|