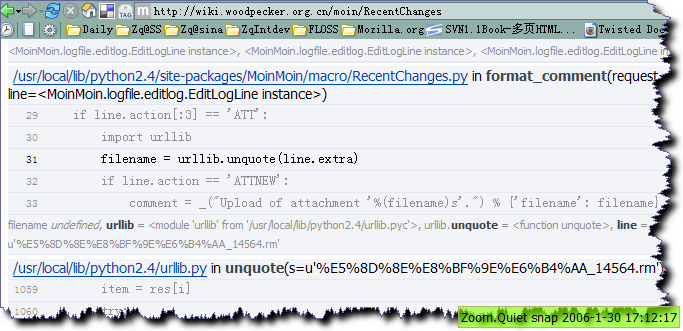
接到举报,看一下子 trackback 是系统 进行字串解析时出错
## site-packages\MoinMoin\macro\RecentChanges.py line 29 左右
if line.action[:3] == 'ATT':
import urllib
try:
filename = urllib.unquote(line.extra)
except:
filename = "filename can not display...maybe UnicodeDecodeError"
if line.action == 'ATTNEW':
try:
comment = _("Upload of attachment '%(filename)s'.") % {'filename': filename}
except:
comment = _("Upload of attachment '%(filename)s'.") % "filename can not display..."
简单过滤就成,但是问题还在…………可怜的中文…………
- t2t渲染:: 2010-10-09 02:21:37
- 动力源自::txt2tags
- 查询报怨:
-
Traceback (most recent call last):
File "/usr/lib/python2.4/site-packages/quixote/publish.py", line 522, in process_request
output = self.try_publish(request, env.get('PATH_INFO', ''))
File "/usr/lib/python2.4/site-packages/quixote/publish.py", line 457, in try_publish
output = object(request)
File "/var/www/douban/luz/__init__.py", line 69, in subject_search
return subject_search_ui(request)
File "/var/www/douban/luz/subject_search_ui.ptl", line 29, in subject_search_ui
main_layout(request, local_content, right_content,right_width=250)
File "/var/www/douban/luz/site_ui.ptl", line 65, in main_layout
<table class="mt"><tr><td valign="top" %s>
File "/var/www/douban/luz/subject_search_ui.ptl", line 114, in local_content
ns, ss = subject_search(text,_items_per_line,start,cat_id=cat_id)
File "/Users/bo/Sites/luzong/search.py", line 409, in subject_search
File "/Users/bo/Sites/luzong/search.py", line 321, in _subject_search
File "/var/www/douban/luzong/sqlstore.py", line 338, in subject_search
self.farm.execute("select id from subject_index where cat_id=%s and match (searchable) against (%s in boolean mode) order by collection_count desc",(cat_id, make_search_string(text)))
File "/usr/lib/python2.4/site-packages/MySQLdb/cursors.py", line 137, in execute
self.errorhandler(self, exc, value)
File "/usr/lib/python2.4/site-packages/MySQLdb/connections.py", line 33, in defaulterrorhandler
raise errorclass, errorvalue
OperationalError: (2006, 'MySQL server has gone away')
Form:
cat 1001
search_text 村上纪香
Cookies:
__utma 164037162.1846512001.1132065229.1138539594.1138604874.113
__utmb 164037162
__utmc 164037162
__utmz 164037162.1138361940.110.3.utmccn=(referral)|utmcsr=koudai8.com|utmcct=/willow/blog/|utmcmd=referral
dbcl 1000030:14e975e18c9cf87a
luz_login 1000030:79376a8b2b63d6fa
Environment:
CONTENT_LENGTH 0
DOCUMENT_ROOT /var/www/douban/
GATEWAY_INTERFACE CGI/1.1
HTTP_ACCEPT text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
HTTP_ACCEPT_CHARSET gb2312,utf-8;q=0.7,*;q=0.7
HTTP_ACCEPT_ENCODING gzip,deflate
HTTP_ACCEPT_LANGUAGE zh-cn,zh;q=0.5
HTTP_COOKIE __utmz=164037162.1138361940.110.3.utmccn=(referral)|utmcsr=koudai8.com|utmcct=/willow/blog/|utmcmd=referral; __utma=164037162.1846512001.1132065229.1138539594.1138604874.113; luz_login="1000030:79376a8b2b63d6fa"; dbcl="1000030:14e975e18c9cf87a"; __utmb=164037162; __utmc=164037162
HTTP_HOST www.douban.com
HTTP_REFERER http://www.douban.com/subject_search?start=15&search_text=%E6%9D%91%E4%B8%8A&cat=1001
HTTP_USER_AGENT Mozilla/5.0 (Windows; U; Windows NT 5.2; zh-CN; rv:1.8) Gecko/20051111 Firefox/1.5
PATH_INFO /subject_search
QUERY_STRING search_text=%E6%9D%91%E4%B8%8A%E7%BA%AA%E9%A6%99&cat=1001
REDIRECT_STATUS 200
REMOTE_ADDR 61.135.152.194
REMOTE_PORT 3944
REQUEST_METHOD GET
REQUEST_URI /subject_search?search_text=%E6%9D%91%E4%B8%8A%E7%BA%AA%E9%A6%99&cat=1001
SCGI 1
SCRIPT_FILENAME /var/www/douban/subject_search
SCRIPT_NAME
SERVER_ADDR 61.129.113.231
SERVER_NAME www.douban.com
SERVER_PORT 80
SERVER_PROTOCOL HTTP/1.1
SERVER_SOFTWARE lighttpd/1.4.8
呜乎哀哉!赶紧报告!
不过看豆瓣的服务架构是挻前卫的哪…………Lighttpd....
动力源自::txt2tags
 OpenSource
,error
,Quixote
OpenSource
,error
,Quixote
- 原先的分类索引
-
指向的页面是将所有文章的正文输出
- logging
-
- 30分钟,学习wbgrecent.py
- 5分钟,使用原版脚本创建
zqcategory.py
;zqcrecent.py
- 30分钟,调试功能
- 20分钟增强CSS
- 85分钟完成心中所想!
- 分析最重要!
-
原先想象的和实现的,完全不同!
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
,css
¶ [fix PyBlosxom]CSS for Opera
 -
晚上回家使用Opera 8.51 才发现这问题…………
= fixed =
- CSS2的兼容性哪…………
-
- 原来如比
-
<a name="1137513213.36"></a>
[Tue Jan 17 23:53:33 2006]
<!-->
<a href="mailto:">123</a>
<sup><a href="">URL</a></sup>
曰::
...
输出中有意外的HTML代码?!
原来是Opera 坚守标准HTML 的结果!!
- 修正
-
将原先
comment.phtm模板中的:
...
<!-- $cmt_title -->
<a name="$cmt_time"></a>
[$cmt_pubDate]
<!--$cmt_link-->
修改为
<!--
$cmt_title
-->
<a name="$cmt_time"></a>
[$cmt_pubDate]
<!--
$cmt_link
-->
一切就正常了!
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
,css
- Why?
-
t2t支持的遗留问题
- 现在我的Blog 基本就两种文件格式:
- .py 脚本文件
- .t2t 文章
- 但是模板中 t2t 额外给出的下载 .t2t和.moin 对 .py 的文件不适用!
- problem
-
模板有效输出值
的说明中有问题!
- file_path just the filename and extensions of the entry
- 实际上没有后缀!
- 所以!
- hacked:
-
path/to/site-packages/Pyblosxom/entries/fileentry.py
#147 line...
self['entryext'] = ext
self['filebasename'] = file_basename
追加我需要的变量!
- 模板处理:
-
这样一来story.*的模板中就可以对应修正输出了!
| <a href="$base_url/$file_path_urlencoded.$flavour"
title="permalink">#
永久链接</a><!--permanent link to this entry-->
<sup>
<a href="/entry/$file_path_urlencoded$entryext">
$entryext</a>
<a href="/entry/$file_path_urlencoded.t2t">
.t2t</a>
<a href="/entry/$file_path_urlencoded.moin">
.moin</a>
</sup>
- contribute 分发!
-
接踵而来的就是如何标准化的反馈社区,
贡献代码了…………
- 进一步的:
-
Pyblosxom的模板属于简单模板,在模板中不能加入逻辑的,
所以现在虽然对.py 的文章有了直接下载链接,但是,没有自动生成的.moin
和约定的.t2t 下载并不应该有…………
向社区建议吧…………
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
,SNS
Djano
是
Python
世界中,类似 RoR
的快速web 开发平台之一.它鼓励快速开发和干净的、MVC设计。它包括一个模板系统,对象相关的映射和用于动态创建管理界面的框架。自从正式发布后在全世界受到追捧,发布的异常快速。
(啄木鸟社区的中文介绍)
CPUG
活跃人物:
limodou
刚刚在个人
Blog
中 发布消息,正式发表了
《Django Step by Step》
-- 《Django一步接一步》中文学习教程!
教程整理自
limodou
的个人学习体验,以前 是以连载的形式在blog中
发布的,此次,使用
reStructed
文本格式整理,组织成为正式教程,通过
啄木鸟社区
空间发布以利于中国Python 爱好者学习。
- 贡献规范
-
约定了开发插件的代码规范!
另外有丰富,标准的API信息:
- 1.3 API
- 1.3 plugin API
- 1.3 callbacks
- 故!
-
可以标准化的安装,hacking 和分享!赞!
- 别传:
-
Response Headers - http://pyblosxom.sourceforge.net/1.3/API/index.html
Date: Fri, 27 Jan 2006 03:31:00 GMT
Server: Apache/1.3.33 (Unix) PHP/4.3.10
X-Powered-By: PHP/4.3.10
Connection: keep-alive
Content-Type: text/html
Transfer-Encoding: chunked
404 Not Found
嘿嘿嘿,无意中发现 PyBlosxom 的服务端使用的是 PHP 发布?!
- 直接使用的
-
- "pycalendar" 日历
- "pycategories" 简要分类
- "pyarchives" 月度归档
- "py" Python 语法颜色渲染
- "comments" 评注
- 少量修改的:
-
- "latest_comments" 最新评注
- 自个儿开发的:
-
- "xhtml" 简单XHTML 文本格式
- 安装未果的
-
- "moinmoin" 格式文本处理器(不支持高版本MoinMoin)
- "trackback" 安装文档看不明(好象也没有人使用TB 哪!)
- 一定要安装的
-
- "commentAPI" 嗯嗯!可以结合Greasemonkey 开发插件式的评注工具哪!
- "folksonomy" 呜乎哀哉!垂涎哪!象美味书签哪样儿的标签化分类
- pyguest
简单留言板
- Will's 系列插件
- plugininfo 自动汇报使用插件情况
- pystaticfile发布静态说明性文章;类似 aboutme 之类的...
- wbgarchives 年度文章汇总页面
- wbggrep grep搜索引擎,嗬嗬!Uinx 系统专用的便利,不用求助于Google/lucene 什么了!
- wbgpager多页指引
- wbgrecent综合"最新"效果:
已经有人问及中文版本的 theme 什么时候发布了!
- contribute 分发!
-
也是技术活,怎么样组织和说明才可以令其它人安然的安装各种插件成功?
不如象 TiddlyWiki 那样儿,
整个完整的,立等可取用的系统合包?
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
,SNS
VI系统现在已经算是门手艺了!在下不行!
但是可以偷哪!
以往各种喜欢的网站,都不太吻合心目中的Blogging space ..
原先想直接 clone Vim 的 desert 颜色系统的…………
但是突然记起了:deviantart

所以....
- 抓取颜色!
-
I Like Your Colors!
塞上CSS的URL;
自动获取
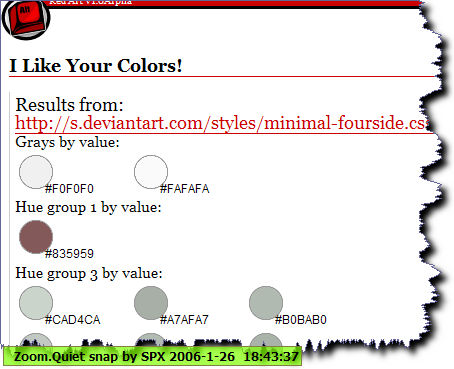 颜色列表,
然后就挥舞CSS就好! 颜色列表,
然后就挥舞CSS就好!
- Flavours的配合
-
这个比较自然,就是在适当的地方,加上适当的
class 或是 id
- 适当的……
-
怎么样是适当的呢?
Plone 模板的DIV 层叠设计就非常的合理,
以前设计过 CZUG.org 的样式
,所以有些体会…………
但是………………
- MainlyGreen
-
此样式,的排版非常古怪,折腾了半天,越调越乱;
最后还是调出自个儿donews 的样式
, 使用 69%-25% 的百分比来组织版块。
- 教训:
-
- CSS 和代码开发一样,没有理解就不能尝试
- CSS 的增长比代码还要快,所以最后应该进行精简
- CSS2 对IE的兼容性,就不要折腾了,先调试FireFox 再 Opera,最后看IE 再不成,就直接禁止IE访问吧…………
- Dive Into Accessibility
-
中文版本:网站亲和力;
- 网站可访问性的官方网站
- 还要继续优化VI
- 现在的问题主要在于:
- 颜色太个性,没有考虑到 弱视力访问者
- 导航太个性,没有考虑到 特殊访问者
- 功能没有完全,不能整体来调优 VI
VI 是艺术性科学,是挑战,要学习……
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
- MD5
-
( Message-Digest algorithm 5)
MD5作为一个单向混淆算法,即不易以逆向运算得到原始资料
Pythonic 的使用:
Python 2.4.1 (#65, Mar 30 2005, 09:13:57) [MSC v.1310 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import md5
>>> dir(md5)
['MD5Type', '__doc__', '__name__', 'digest_size', 'md5', 'new']
>>> md5.md5(文件)
<md5.md5 object at 0x00B83800>
>>> md=md5.md5(文件)
>>> dir(md)
['copy', 'digest', 'hexdigest', 'update']
>>> md.hexdigest()
'50235d71d6aa33a2be8d8bfbb1e87b91'
嗯哪……
- 动力源自::txt2tags
- t2t渲染:: 2011-09-07 03:51:34
chinese
,OpenSource
,pythonic
,md5
- Technorati Profile
-
Technorati Link
支持 Technorati 的分众分类 首先要如此:
- Step 1: 创建一新文章
- Step 2: 复制此链接(Technorati 自动生成的)到文章中:
- Step 3: 发布到你Blog 中
全部作好?开始让 Claiming 你的Blog
chinese
,Zen
,internet
,Folksonomy
- 动力源自::txt2tags
- t2t渲染:: 2010-10-09 02:21:40
- solidot.org
-
Geek新闻中心 中文版本
今天看突然变成这样子:
呜乎哀哉!技术新闻站点哪!
看的也是非常古老的发布配置…………
chinese
,Zen
,internet
- 动力源自::txt2tags
- t2t渲染:: 2010-10-09 02:21:40
¶ [RE:]一个程序员的博客 开源机会还要等10年?
http://my.donews.com/qianlaohu/2006/01/22/
不知道哪位兄弟,快速引用了还没有发表的报纸文章…………
嗬嗬;-) 不知道怎么讲…………
奋起
每日至少抽一刻钟解答列表中初学者的问题,
每周至少抽两小时整理新学知识,发表体验 Blog/Wiki/mail 分享出去,
每周至少抽四个小时来翻译自个儿喜欢的自由软件的文档,
每月至少抽八小时编程,推进自个儿的项目,
每年至少参加一次自由软件的活动,传播自由软件思想,发展一名自由人……
只要我们每个人都坚持下去……
10年!就足以改变中国软件的整体风貌!
宣言是啄木鸟社区的大家共同约定的不是俺一个人的哪……
Quiet
,news
,nomeans
- 动力源自::txt2tags
- t2t渲染:: 2010-10-09 02:21:42
在本地使用自个儿习惯的格式来写,通过SVN 自动版本同步到PyBlsxom发布!
- 好处:
-
- 天然的备份!
- 离线写作!
- 本地搜索!
- 自然备份!
- 强力版本管理!
- 灾难恢复简单
- Blog系统定制权限容易管理
- ...
- 坏处:
-
- 要学习TortoiseSVN 的使用
- 要修正Blogging 习惯..
- 幸好有积累:
-
- HOOKs 脚本:
-
- 关键代码:
在post-commit 事务中插入:
...
upsvn = "%s update %s"%(self.SVN,(aim+mod) )
fup = os.popen(upsvn)
up = fup.read().strip()
self.chkpybt2t(up
,"pyblosxom/zoomquiet/data/")
- 专用t2t 处理函式:
def chkpybt2t(self,dirs,mark):
"""auto check PyBlosxom .t2t blog
"""
for l in dirs.split():
if mark in l:
self.autot2t(l)
def autot2t(self,upath):
"""自动处理t2t 到对应PyBlosxom 目录
- upath svnlook 出来的对应更新记录
- t2t 文件本身输出 xhtml ,cp为txt 由PyBlosxom 显示
- 另外输出为.moin 的wiki 文件
--target moin
"""
t2txhtml = "%s %s"%(self.T2T,upath)
t2tmoin = "%s %s %s"%(self.T2T," --target moin ",upath)
try:
r, w, e = popen2.popen3(t2txhtml)
r, w, e = popen2.popen3(t2tmoin)
r.close()
e.close()
w.close()
except:
# 日志处理
print >> self.f,"~"*7+"t2t::popen2.popen3() ::crash"
- 通过标准的t2t 命令行来输出两种格式的文件 .xhtml和.moin 的
- 特别的 为了定制方便,将 txt2tags 的执行文件专用化:
self.T2T = "/path/to/my/PyBlosxom/plugins/preformatters/txt2tags"
以便进行定制修改
- 已经完成的:
-
- 由 SVN hooks 在每次检入时,自动检测是否为指定模块中的 .t2t 文件?
- 如果是:
- 再调用t2t 输出两种格式的文件
txt2tags /path/to/the/.t2t
txt2tags --target moin /path/to/the/.t2t
- 现在要最终处理的:
-
- 如何令PyBlosxom 解析 .xhtml 到页面中?
- 默许的是仅仅识别 html/纯文本格式的 .txt 文件的
- 参照已有的py.py 预格式脚本:
- 特别的:
-
没有最好,只有更好!
- 现在:
-
- 通过 SVN 在本地使用t2t 格式来写作
- 通过 SVN hooks 自动处理服务端的文章输出
- PyBlosxom 中的专用格式处理脚本,识别并辅助处理了 xhtml 输出!
- 但是:
-
不能聪明的识别不同的原始文件来提供下载哪!
如果是 .py 的,在 永久链接 .t2t .moin 处的其它链接就有问题!
- 询问列表,却没有人回答:
发件人: will guaraldi <[email protected]> 邮送域: lists.sourceforge.net
收件人: [email protected]
日期: 2006-1-25 上午12:15
主题: [Pyblosxom-devel] will's status
Just as an fyi, my email client is still having problems with Zoom's
emails so I haven't read any of them yet.
I also started classes a week and a half ago and I'm working part time
this semester. As such, I'm going to be laying low on PyBlosxom stuff
including fielding user requests and help for a while. I'll try to get to
bugs and user isues at least once a month.
I am also still sitting on a contributed plugins release--that's first
priority. I need to go through and fix the logging issues on plugins I
don't use.
/will
- 呜乎哀哉!看来 Gmail 并不是完美的哪!俺的询问邮件没有中文字符的哪!
连标点也不敢使用中文的...
- PyBlosoxm模板中有效变量
-
但是!
- file_path just the filename and extensions of the entry
- 就是仅仅输出了文件名儿,没有后缀的说
- 开源项目的文档是极其重要的组成部分,有多少项目是因为文档不全而自然消亡的哪…………
- 技术文档樣文:
-
日本人作的就是要好些:
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
PREFORMATTER_ID = 'txt2tags'
#tags Zen,pythonic
FILE_EXT = 't2t'
__version__ = '$Id: tryt2t.py,v 2872b22e2ace 2011/10/27 07:08:25 zoomquiet+hg $'
__author__ = 'Zoom.Quiet '
#T2T = "/usr/local/bin/txt2tags"
T2T = "t2t"
def cb_entryparser(args):
args['t2t'] = parse
#args[FILE_EXT] = readfile
return args
"""
def parse(filename):
#html = publish_string(story, writer_name='html')
import os
act = T2T+" -t html -H --toc %s"%filename
html = act
html += os.popen(act).read().strip()
#return html[html.find('') + 6:html.find('')]
return html
"""
#def parse(filename, request):
def parse(filename):
import os, sys
from StringIO import StringIO
# open own source
#config = request.getConfiguration()
act = T2T+" -t html -H --toc -o - %s"%filename
#source = open(filename).read()
#out = StringIO()
#html = os.popen(act).read().strip()
print act
#print os.popen(act).read().strip()
# write colorized version to "python.html"
#Parser(source, out).format(None, None)
#print out.getvalue()
"""
entryData = {'body' : out.getvalue(),
'title' : filename.replace(config['datadir'], '')}
return entryData
"""
parse("py-code-rule.t2t")
- http://pyblosxom.sourceforge.net/1.3/manual/c651.html
-
默许提供:: txt(html),genericwiki,moin,py,txtl,rst文本格式来Blogging!
- 标记签文本:
- .txt(html) 不用说,麻烦!不用!
- 自然文本:
- .py 咳咳咳,只能代码引用时哪!而且没有行号也要修改
- 结构化文本:
- .rst 丰富!强大!但是复杂!难用,内存也占的大
- .txtl 很好,但是依赖很多系统工具
- .moin 赞!但是不支持MoinMoin 1.3.x 以后的不会hack ,问了,也没人回复,呜乎哀哉
- .genericwiki 用过MoinMoin 的人,绝对不想这种原始 wiki 格式的!
怎么办,什么都不顺手!
那未就自个儿DIY!
安装 txt2tags 先:
- 在FreeBSD 中有内含的!
#cd /usr/ports/textproc/txt2tags
#make install clean
- 需要按照说明,将 txt2tags 执行文件复制到
/usr/bin 中
保持 是我的本意 是我的本意
- 发布流程
-
我设想的Blogging flow:
- 本地撰写
- 上传系统
- 自动生成多格式文件
- PyBlosxom 发布 .xhtml 的
- 同时提供 .t2t 原件和 .moin 格式的下载
- 对应支持
-
已经可以进行的:
- 本地撰写 -- Leo
- 上传系统 -- 透过 SVNhookscript自动从服务端检出到对应目录
- 自动生成多格式文件 -- ?是SVN hooks 还是创建 t2t.py 预格式化处理?
- PyBlosxom 发布 .xhtml 的 -- 设置默许格式就好!
- 同时提供 .t2t 原件和 .moin 格式的下载 -- 模板的处理
嗯哪…… 这样一来,格式漂亮的文章,
根本就"八股化" 了! 在 Leo 中,仅仅保持固定的几个预定义节点,
其它的就不用理会,随便写,怎么样都会自动组织成非常规范的文章,
比在各种Blog 系统中,所谓WYSIWYG编辑环境中,反复调整不得,
结构化文本的WYTIWYG是绝对快感的! 这样一来,格式漂亮的文章,
根本就"八股化" 了! 在 Leo 中,仅仅保持固定的几个预定义节点,
其它的就不用理会,随便写,怎么样都会自动组织成非常规范的文章,
比在各种Blog 系统中,所谓WYSIWYG编辑环境中,反复调整不得,
结构化文本的WYTIWYG是绝对快感的!
- 王垠很早有介绍
所见即所得vs所想即所得
- 有诗证曰:
文本文件好
工具遍地跑
程序两三行
全部改好了
哈哈哈!
= TODO =
Blog 不同于静态文章,需要有一些SNS配合的输出,t2t 没有进行专门的支持,要进行深入hack:
- technorati支持
-
链接要类似
<a href="http://technorati.com/tag/nomeans" rel="tag">nomeans</a>
有rel="tag" 声明! t2t 输出的链接没有!
hacking!
- xhtml 的输出:
-
每篇Blog的原文通过 Leo 的节点共用统一的格式声明:
%%date(%Y-%m-%d %I:%M:%S)
%! Target : xhtml
%! Encoding: UTF-8
%! Options : --toc --css-sugar --enum-title
要求 t2t 输出为 xhtml格式,以utf-8 编码,
要整理出章节索引,并以CSS样式友好的形式组织,并数字式列表之!
- 要fixed的问题:
- 完整的 xhtml 输出含有 head标签内容,
这样一来PyBlosxom输出时一页会含有多个head,不利于搜索,也浪费数据!
但是
--no-headers参数的输出 却没有了主副标题的组织,两难哪!
- 索引链接的 anchor 输出,太简单!如果一页内含了多个t2t 输出页面的话一定有冲突!
需要学习MoinMoin 的索引锚点,加入hash的混淆区分!
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
¶ [樣文]FreeBSD unionfsの改善提案
- 发现:
-
中国FreeBSD commiter 之一的 delphij 发现吿之的
简单列一下子文档结构
作者
修改log
其它版本链接[English]
文档本身的简单述
简介讨论主体本身
简述已知问题
描述如何改善
说明如何升级
说明新环境如何使用
说明对以往系统的补丁发布情况
...
具体说明每次更新的变化
还有什么不足?
呜乎哀哉!标准的一次软件升级,就应该为用户负责道明白前因后果;
我们呢…………?
- t2t渲染:: 2010-10-09 02:21:41
- 动力源自::txt2tags
看过情颠大圣,被其中的两句话打动,于是就觉得还是不枉我一早努力和睡懒觉做搏斗的辛苦。
世间安得双全法,不负如来不负卿!,这话读来不像佛教教义,但是也不像凡人写的,于是上网查询,发现原来真的是出自高人之手。
“那一月我摇动所有的经桶,
不为超度,只为触摸你的指尖;
那一年磕长头在山路,
不为觐见,只为贴着你的温暖;
那一世转山,不为修来世,只为途中与你相见.”
----仓央嘉措
仓央嘉措有一个称号:六世达赖喇嘛。也许听到这里,大家都会肃然起敬。但如果仅仅如此,也许我并不会动心。先来看看关于他的一段官方历史:
生于康熙二十二年,十四岁时剃度入布达拉宫为黄教领袖,十年后为西藏政教斗争殃及,被清廷废黜,解送北上,道经青海今纳木措湖时中夜循去,不知所终。
守门的狗儿呀
你比人还机灵
别说我黄昏出去
别说我清晨才归
这是仓央嘉措在和玛吉阿米约会时候写的文章。玛吉阿米是活佛在一次酒馆中偶遇的女子,如月亮一般美丽。这所小酒馆现在还在拉萨的帕廓街,是一座黄色的楼房,房主人以此为荣耀,黄房子三百年金色不改。现在那里已被改造成一处咖啡馆,招牌上用藏、汉、英文赫然书写着店名——“未嫁娘”。
门达旺是门隅地区的首府。在门巴人的传说中,太阳名叫“达登旺波”,意谓七匹马拉的车,达旺就是达登旺波的简称。七匹马的太阳车辚辚过处,还生长着门巴人起源的爱情故事,说的是明镜般的湖水中走出一位美男子,怎样以月亮为弓,以流星为箭,将定情的靴带射向美丽的姑娘;这里还生长着卓瓦桑姆的美丽传说,说的是天女化身的贫家姑娘卓瓦桑姆怎样与嘎拉王一见倾心,后来又怎样遭致反面人物王后的迫害,最终善战胜了恶,美战胜了丑。仓央嘉措就是在这样的故事环境中长大的。他的父亲是藏族,母亲则是门巴族人。在这藏族和门巴族聚居地,两个民族的文化相异而又交融。这是仓央嘉措的幸运,也是仓央嘉措的不幸。因为生在红教区,他向往着爱情。而黄教则是唯一一个限制结婚和情欲的藏传佛教。
与其他转世灵童不同,由于历史的阴差阳错,仓央嘉措并非自小被迎请入宫,因此他是在天籁中长大的。当年五世喇嘛圆寂。第悉·桑结嘉措作为摄政王正当其政,那个人上对朝廷下对人民隐瞒了真相,长达15年之久秘不发丧,只在私下里秘密查访转世灵童。这一事件改变了仓央嘉措人生的轨迹,揭开了他悲剧命运的序幕。如果仓央嘉措一辈子只生活在东山顶上,也许他会幸福;如果他一生下来就成为活佛,也许同样的他会幸福;可是没有。两样对他来说都是惘然。虽然藏史声称两三岁时就将他隐秘地转移并教授佛法,但民间的说法则让他一直在家乡成长到15岁。我宁肯相信后者,不然何以解释那个自由的性灵和人间情怀缘何而来。
其时西藏上层统治阶级内部关系错综复杂,明争暗斗:位高权重的摄政第悉·桑结嘉措与朝廷册封的蒙族汗王的藏蒙之间,以及蒙族人内部矛盾冲突日益白热化,局势动荡不安,正值一次政治大地震前夕。无心于政治也无心于佛身的仓央嘉措被迫参与其中,满心的厌倦与失望。他看不到未来,一切都无从逆料。心灰意冷,彷徨无倚。任凭第悉好言规劝或严厉申饬,年轻的活佛只是不思学经。
用墨写下的字迹
一经雨水就洇湿了
没能写出的心迹
想擦也擦它不掉
仓央嘉措的眼睛和心不属于布达拉宫。深夜的雪地上开始踏出一行脚印,从布达拉宫一直伸向帕廓街;一个名叫宕桑旺波的高贵儒雅青年出现在街头的酒肆中。虚幻的物质世界多么诱人,假如真有来世,我愿生生世世为人,只做芸芸众生中的一个,哪怕一生贫困清苦,浪迹天涯,只要能爱恨歌哭,只要能心遂所愿。
想她想的放不下
如果这样去修法
在今生此世
就会成佛了吧
戒律森严的环境和多情的内心世界、角色和天性的冲突,终于在20岁那年不可遏止地爆发了。曾为少年仓央嘉措落发授戒的五世班禅大师,五年后又该再次为之授比丘戒了。仓央嘉措依约去往日喀则扎什伦布寺,满脸的乌云密布。我们无从得知一路上他想了些什么,我们所看到的只是他的决心已定。经由五世班禅自传我们得知了结果:班禅大师祈求劝导良久,仓央嘉措沉默以对良久,然后毅然站起身来,夺门而去。他双膝下跪在日光大殿外,给大师磕了三个头,反反复复只说一句话:“违背上师之命,实在感愧”,念念叨叨黯然而去。在后来的许多天里,不仅没有转机,甚至变本加厉:不仅拒受比丘戒,反而要求大师收回此前所受的出家戒和沙弥戒。说这番话的时候,仓央嘉措痛彻肺腑:“若是不能交回以前所受出家戒及沙弥戒,我将面向扎什伦布寺而自杀。二者当中,请择其一!”
这就是仓央嘉措,惟一不再的仓央嘉措,无可奈何的仓央嘉措。他从来就身不由己,他的命运全由别人来安排。他甚至不如一个农奴还有逃亡的自由,甚至不如一个小僧也有还俗的自由。他是藏传佛教第一人,他拥有的是最多的不自由。说那番话的时候,他的心在流血吧。
从那以后,我们看到的仓央嘉措,就是一个放浪的活佛。他没有办法选择,但是他决定背叛,即使这种背叛极为危险,并且,终于成为了悲剧。回到那首诗的结局。狗遵从了活佛的意愿,然而天没有。在破晓时分,人们读着男人在雪野里清晰地印下的夜奔的足迹,那足迹急促而有力,人们疑惑,沉思,继而惊愕。这些蜿蜒连接着布达拉宫和小巷深处的脚印,在坦然以爱情的名义歌唱的同时,也写下了对宗教的背叛。
神圣庄严的宗教律例不可能容忍出轨的离经叛道。仓央嘉措就这样因“耽于酒色,不守清规”而被康熙帝予以废立。年仅24岁。
没有人知道他是怎样在监视的目光下仓惶走在逃亡的路上,也没有人知道他的卒年及准确的圆寂之地。此去无痕,有人说是在烟波浩渺的青海湖畔被水肿夺去了年轻的生命,有人说是被清朝皇帝软禁于山西五台山并圆寂于当地,有人说是在藏南一山洞坐化,又说是决意遁去,周游印度、尼泊尔等地。有一个非常戏剧性的细节,当人们迎接六世达赖的灵童的时候,大家发现灵童居然就在玛吉阿米的故乡……
庄严肃穆的布达拉宫,这历代喇嘛的驻锡地。它以尊荣显赫的姿态永远地拒绝了仓央嘉措。在西藏的历史上,曾经一共产生过十四辈达赖喇嘛,除却第一代达赖的灵塔在扎什伦布寺外,其它历代达赖喇嘛总有灵塔、塑像、绘画等纪念物供奉在布达拉宫,即使人们不怎样提及的只活了十一岁的九世达赖、只活了十八岁的十一世达赖都有他们的灵塔在,然而,声名远扬的六世达赖仓央嘉措呢?塑像是不会再铸的了,壁画中也看不见他的影子,至于灵塔的安置,布达拉宫说,他?不配。
然而,他的诗却传遍了前藏、后藏,传遍了藏北、藏南,传遍了古老的山南。传遍了大江南北。
喇嘛仓央嘉措
别怪他风流浪荡
他所追寻的
和我们没有两样
这就是仓央嘉措最后的结局,三百年来我们一直传唱这首歌,只为了仓央嘉措,一个不成功的活佛,然而却是一个伟大的诗人。
读完这段回头再看他流畅轻盈的情诗,感受蕴涵其中的偷偷的喜悦,对世俗不畏惧不张扬的态度,想起三个字“不容易”。原来情诗中也有禅,不管外界多么纷繁嘈杂,心内始终平静如砥,爱情始终明澈快意,这就是爱他的理由。
让我们再看仓央嘉措最传世的一首诗:
那一月我摇动所有的经桶,
不为超度,只为触摸你的指尖;
那一年磕长头在山路,
不为觐见,只为贴着你的温暖;
那一世转山,
不为修来世,只为途中与你相见
而“不负如来不负卿”的原诗是:
曾虑多情损梵行,
入山又恐别倾城.
世间安得双全法,
不负如来不负卿!
我佛慈悲!
从这里,到那里 流转的不仅仅是 生命迁徙的轨迹
- 动力源自::txt2tags
- t2t渲染:: 2010-10-09 02:21:40
- http://pyblosxom.sourceforge.net/1.3/manual/c857.html
-
怎么着?一个最普通的评注要这么复杂才能够成功?!
呜乎哀哉…………
- 速度
-
为什么 PyBlxosom 的 comment 时的响应速度如此慢?!
- 果然不是 XML 的事儿!
- 是 smtp 发送提醒邮件时失败而长期等候,只能 不使用提醒先睹
草看了一下子 comments.py 真是牛哪!
from xml.sax import make_parser, SAXException
- 使用 sax 事务性XML解析器进行的处理,
- 作者Ted Leung是
 《Professional XML Development with Apache Tools》的作者!怪不得使用这么专业的处理手法 《Professional XML Development with Apache Tools》的作者!怪不得使用这么专业的处理手法
- 情急乱投医时有邮件往来:
发件人: Ted Leung <[email protected]> 邮送域: sauria.com
收件人: Zoom Quiet <[email protected]>
日期: 2006-1-24 下午2:54
主题: Re: [bug]comments recoder double info. ?
...
I am no longer maintaining the comments plugin. The appropriate
place to get the answer to your question is pyblosxom-devel. I get
several hundred e-mails per day, and you are doubling your share of
the traffic by copying me personally. I see the messages that go to
pyblosxom-devel. There is no need to send me an extra copy.
- 嗬嗬 不是第一次向他批发询问邮件了,还如此好脾气的指导,大师的风范!学习之!
- 其实通过将毎条评注依照对应的目录,分布记录在文件系统中,
然后使用XML集中进行处理,实在是最明快的处理方式了,只是没有提供管理的入口?
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
- http://pyblosxom.sourceforge.net/1.3/manual/c218.html
-
反复尝试不果!
终于发现是版本问题,要使用1.3 自带的Flavours才可能成功运行
…………呜乎哀哉!!
本来仅仅是要先安装一个最基本的PyBlosxom ,结果一折腾牵出了各种问题,工具的理解,定制...
模板,PyBlosxom 中叫 Flavours,其实就是和系统配合的简单Python 模板系统,
和我们在CherryPy 或是 Python 默许的模板系统中一样
$var 安放在HTML 中,通过渲染输出最终页面
只是 PyBlosxom 升级到 1.3.0 以后各种变量都有变化,于以前的模板完全不能兼容,而且 contrib--工具集也没有释放,可以下载的 contrib.1.2.2仅仅针对 v 1.2x版本的系统,
反复了几次,还是老实的从 sf.net 的CVS 中检出最新版本的,这才成功.
特殊的,根据以往经验进行了web server 的配合发布
+--flavours 各种模板
| +--atom.flav
| +--error.flav
| +--html.flav
| +--phtm.flav
| +--rss.flav
| \--rss20.flav
+--plugins 各种插件使用
| +--comments
| +--lucene
| +--meta_plugins
| +--preformatters
| \--xmlrpc_plugins
\--zoomquiet 我的PyBlosxom 实例
+--cache
+--comment 评注数据
+--data Blog 内容
| +--OpenSource
| | +--...
| \--Zen
| +--...
+--log 日志
+--stat 统计数据
+--static 静态页面存储
\--web web 服务发布
在Apache 中:
Alias /styles "/path/to/flavours/"
<Directory "/path/to/flavours">
...
Alias /entry "/path/to/zoomquiet/data/"
<Directory "/path/to/zoomquiet/data">
...
- /styles
-
样式发布目录,来为将来的多用户分享模板作准备
- /entry
-
内容发布目录,为将来的日志正文下载作准备
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
- 定制tips:
-
如何快速定制地址栏旁边的搜索引擎?
- 手工修改:
Mozilla.org\FireFox\searchplugins\
- 其中的图片和对应的 .src
- 重启 FireFox!
- 注意:
-
.src 中的:
<browser
update="https://addons.mozilla.org/searchplugins/updates/google.src"
updateIcon="https://addons.mozilla.org/searchplugins/updates/google.gif"
updateCheckDays="1"
>
可清 以免自动更新掉!
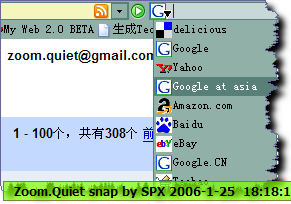 -
我为了使用 google 定义了 asia.google
; google.cn
两个引擎
- t2t渲染:: 2010-10-09 02:21:41
- 动力源自::txt2tags
OpenSource
,Mozilla
,FireFox
- http://pyblosxom.sourceforge.net/1.3/manual/x74.html
-
任何一步都不能少!!!
折腾了几天才发现,默许的只识别 .txt 文件的!!
原先就是在 BSD 中只安放了 "firstpost" 文本文件,
所以,一直报怨没有找到页面的输出…………呜乎哀哉!!
一个实用的,简练的Blog 系统到底需要哪些功能?
- 按照用户喜欢的格式来写
- 样式可定制
- 备份方便
- 有SNS功能
齐了!其它的各种功能不过是对应的加强了
- [PyBlosxom http://wiki.woodpecker.org.cn/moin/PyBlosxom?]
-
是blosxom的Python Clone
反正,是轻型的个人Blog 系统,就当作Python 应用练习了!
Pure Python 系统哪!嗯哪……就是求个Cool.
动力源自::txt2tags
OpenSource
,PyBlosxom
,hacking
在本地使用自个儿习惯的格式来写,通过SVN 自动版本同步到PyBlsxom发布!
- 好处:
-
- 使用DB4有事务支持
- 二进制文件可版本管理
- 速度快!
- 离线操作丰富
- ...
- 坏处:
-
- 使用DB 数据可能变脏
- DB4 管理复杂
- 不过,到了1.2.1以后也支持CVS样儿的文件型数据管理了
-
很早就使用SVN 进行代码管理了,统一的体验就是快!
trac of 啄木鸟
啄木鸟SVN使用说明
- FreeBSD6.0 为准:
-
- 升级ports:
portsnap upgrade
- 比以前的什么
cvsup -sgL2 /usr/share/examples/cvsup/ports-supfile -h cvsup{,2-6}.cn.freebsd.org
要直接的多
- 安装SVN:
# cd /usr/ports/devel/subversion
# make install clean
- 创建SVN仓库:
svnadmin create --fs-type fsfs /path/to/ur/svnrepo
- 建立使用 FSFS 存储的仓库
- 启动服务:
- 选择svnserve:
- 根据对比
- svnserve 模式依赖最小,管理也方便,速度还快!
- inetd 方法启动:
- 作为独立“守护”进程:
- 权限管理:
- 1.3.0 的SVN提供了足够好用的默许权限控制!
不用什么 Apache 的额外支持就足够进行管理了!
- svnserve.conf中指定:
password-db = passwd
authz-db = authz
...
- 就可以在 passwd 文件中定义口令
[users]
harry = harryssecret
sally = sallyssecret
...
- authz 中进行用户组,代码目录访问权限的分配了
[groups]
harry_and_sally = harry,sally
[/foo/bar]
harry = rw
* =
[repository:/baz/fuz]
@harry_and_sally = rw
* = r
- 比以前的只能口令,要丰富,足够的很多了!
- 备份管理:
- 事务管理:
以上是快记,具体使用中的体会,妙处要长期发现记录在案 的…………
- 动力源自::txt2tags
- t2t渲染:: 2010-10-09 02:21:36
OpenSource
,hacking
|


 ;来自
;来自